
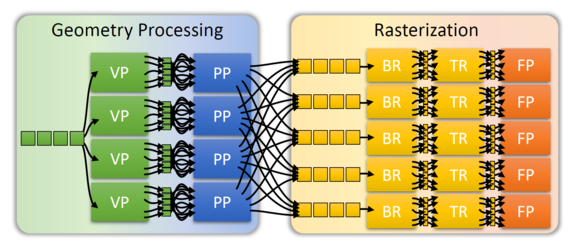
 Pipeline designs are important in many areas of computer graphics. They allow streaming input data to become available gradually, and allow individual pipeline stages to be executed in parallel for different input elements. Moreover, pipeline stages are easily understood, reused and extended. Consequently, pipelines are used for realtime graphics (OpenGL/D3D), production rendering (Reyes), visualization, 3D printing and many more. The graphics processing unit (GPU) uses a hardware pipeline, but is designed for high efficiency rather than flexibility. Some stages allow programmable shaders, but the overall architecture is static. The order of stages cannot be changed, and several of the stages are fixed-function units with only minimal freedom for configuration. This inflexibility restricts research and development. New rendering architectures, which do not follow the predefined pipeline, can never compete with approaches that fit the hardware pipeline.
Rather than waiting for hardware vendors to change or open up their designs, we propose to build a flexible, configurable software rendering platform that runs on the programmable compute units of current graphics processors, targeting modern GPU compute languages such as CUDA. Our platform supports the generation of arbitrary pipeline designs with an unrestricted number of pipeline stages, freely configurable intermediate data and stage connections. This flexibility is achievable by modeling all stages as well as stage connectors in software. The key element for achieving high performance is scheduling the pipeline workload to the execution cores in an optimal manner.
To achieve these goals, we will investigate new ways to schedule graphics workloads, achieve work distribution between pipeline stages and support recursive pipelines with bounded memory. On top of the new rendering architecture, we will investigate advanced concepts such as frameless rendering, and non-linear rasterization. With the success of this project, we will provide the basis for novel research in the field of real-time rendering. We will help to envision new rendering pipelines, guide and inspire new hardware designs, and show that rendering techniques currently believed to be infeasible can run in real-time on current hardware. As with our previous research results, we plan to release our code under a permissive open- source license to motivate future collaborations.
Pipeline designs are important in many areas of computer graphics. They allow streaming input data to become available gradually, and allow individual pipeline stages to be executed in parallel for different input elements. Moreover, pipeline stages are easily understood, reused and extended. Consequently, pipelines are used for realtime graphics (OpenGL/D3D), production rendering (Reyes), visualization, 3D printing and many more. The graphics processing unit (GPU) uses a hardware pipeline, but is designed for high efficiency rather than flexibility. Some stages allow programmable shaders, but the overall architecture is static. The order of stages cannot be changed, and several of the stages are fixed-function units with only minimal freedom for configuration. This inflexibility restricts research and development. New rendering architectures, which do not follow the predefined pipeline, can never compete with approaches that fit the hardware pipeline.
Rather than waiting for hardware vendors to change or open up their designs, we propose to build a flexible, configurable software rendering platform that runs on the programmable compute units of current graphics processors, targeting modern GPU compute languages such as CUDA. Our platform supports the generation of arbitrary pipeline designs with an unrestricted number of pipeline stages, freely configurable intermediate data and stage connections. This flexibility is achievable by modeling all stages as well as stage connectors in software. The key element for achieving high performance is scheduling the pipeline workload to the execution cores in an optimal manner.
To achieve these goals, we will investigate new ways to schedule graphics workloads, achieve work distribution between pipeline stages and support recursive pipelines with bounded memory. On top of the new rendering architecture, we will investigate advanced concepts such as frameless rendering, and non-linear rasterization. With the success of this project, we will provide the basis for novel research in the field of real-time rendering. We will help to envision new rendering pipelines, guide and inspire new hardware designs, and show that rendering techniques currently believed to be infeasible can run in real-time on current hardware. As with our previous research results, we plan to release our code under a permissive open- source license to motivate future collaborations.