Demand Forecasting
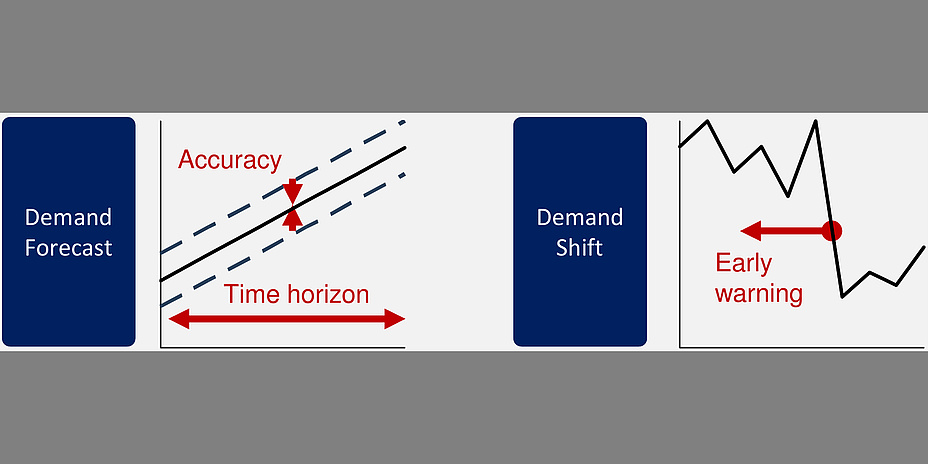
The AT&S Demand Forecasting project employed big data techniques to address two use cases: forecasting the evolution of demand in the smartphone market and issuing early warnings of possible large shifts in demand.
In the particular case of the smartphone market, where new products are released in very short cycles, it becomes imperative to forecast and identify heavy shifts in market demand as soon as possible. We employ a big data approach to forecast market demand and to issue early warnings on market-changing events in the smartphone business.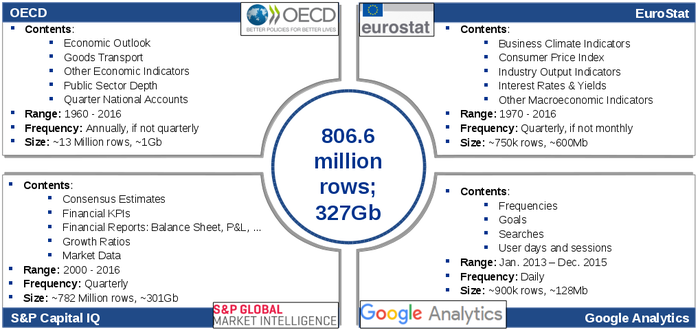
Roman KERN
Dipl.-Ing. Dr.techn.
Institute of Interactive Systems and Data Science
Inffeldgasse 13/VI
8010 Graz
Phone: +43 316 873 30860
<link int-link-mail window for sending>rkern@tugraz.at
Globalization and rapid technological development are becoming increasingly important challenges for industrial enterprises. In particular, they need to adjust planning and production to preempt changes in complex and volatile markets. To that end, it is crucial to monitor and identify market changes, which potentially impact market demand. For example, consider the case of famous manufacturers of cell phones from 10 years ago. These vendors were at some point in time the dominant force in the mobile phone and smartphone markets. However, their market shares collapsed rapidly, and they either vanished from the market entirely or they play minor roles today. Such significant changes in the market greatly impact the plans and performance of electronic parts suppliers, which need to plan their production pipeline often semesters in advance.
In the AT&S Demand Forecasting project, we devised a big data approach to first prototype an early warning system on fundamental changes, and secondly forecast mid-term trends in smartphone market demand. This project was a cooperation between AT&S, an Austrian high-end printed circuit board manufacturer, the <link https: www.tugraz.at en institutes iim home _blank int-link-external external link in new>Institute of Innovation and Industrial Management (TU Graz) and the Know-Center, Austria’s leading research center for data-driven business and big data analytics.
Big Data
In the context of this project, big data consists of both internal data from AT&S's enterprise resource planning and accounting systems as well as external data sources, such as financial indicators from Standard & Poors and economic indicators from EuroStat or OECD. The latter group of datasets includes data on macro-economic factors and data specific to the printed circuit board industry. In total, we processed more than 300 gigabytes and more than 800 million instances of both internal and external data. Processing data is, in this sense, an approach consisting of multiple steps. We begin with data extraction, which entails gathering data from numerous different data sources, each with different data formats. Then, we transform and clean these different data sources into a single common data structure. Finally, we upload this processed data to the Know-Center Big Data Cluster, a set of machines comprising a total of 144 Intel Xeon CPU cores, 1.5 terabyte RAM, and 180 terabyte disk space.
This figure depicts some of the contents of the big data sources analyzed in this project. We highlight the total amount of rows and data size and we omit further details on AT&S’ internal data sources.
Taming the data deluge
We address the project objectives with tools from time series analysis, of which an infinite amount can be extracted from the data we gathered. Employing domain and business knowledge, we find a suitable set of time series to be analyzed. We narrow down the number of time series further by selectively filtering those with desirable properties such as high direct and lagged (cross-) correlation with smartphone market demand. This filtering step reduced the amount of time series to analyze from tens of millions to tens of thousands. Then, we model the market demand forecast and shift detection problems as separate time series outlier detection and forecast problems.
Tackling the use cases
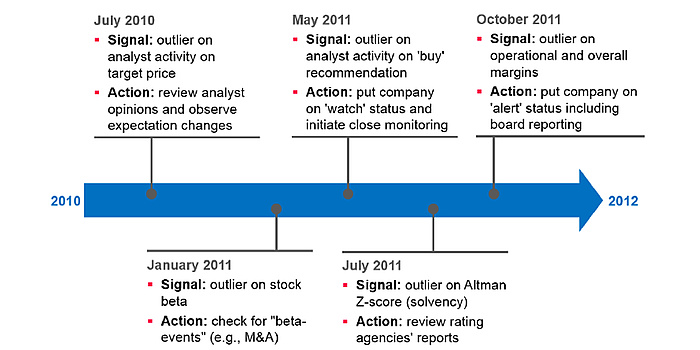
As far as the market demand shift detection problem is concerned, we focused on identifying the downfall of a major vendor in the smartphone market with respect to a peer group of unaffected ones. To identify such an event, we derived a set of 23 market indicators, where that major vendor performed significantly different than its peer group. In this context, “significantly different” is the result of an outlier score. This outlier score summarizes the amount of indicators where a given vendor’s performance significantly deviates from average peer group performance. Using the outlier score, clear signals indicated outlier behavior in the major vendor up to 6 months prior to its significant loss of market share. These signals can form the basis of an early warning system with a dedicated action plan.
Regarding the demand forecasting problem for the smartphone market, we aimed to provide both a categorical and a continuous forecast on the evolution of the smartphone market demand growth 12 months into the future. We categorized market demand growth in three classes (strongly negative, around zero and strongly positive growths) and trained a number of classifiers, such as Support Vector Machines, to use our reduced set of tens of thousands of time series to output one of those three classes. Furthermore, we derived a linear model to forecast smartphone market demand growth as a linear regression of, again, our reduced set of tens of thousands of time series. Both the classifier as well as the forecasting model captured overall market trends.
A set of five metrics indicates outlier behavior successively observed in a major smartphone vendor significantly deviating from the market and its peers’ performance. This exemplary outcome of our project can be used to create an early warning system with a dedicated action plan.
Kontakt
Dipl.-Ing. Dr.techn.
Institute of Interactive Systems and Data Science
Inffeldgasse 13/VI
8010 Graz
Phone: +43 316 873 30860
<link int-link-mail window for sending>rkern@tugraz.at


