
Efficient 3D Tracking in Urban Environments with Semantic Segmentation
Summary
We present a new 3D tracking approach for self-localization in urban environments. In particular, we build on existing tracking approaches (i.e., visual odometry tracking and SLAM), additionally using the information provided by 2.5D maps of the environment. Since this combination is not straightforward, we adopt ideas from semantic segmentation to find a better alignment between the pose estimated by the tracker and the 2.5D model. Specifically, we show that introducing edges as semantic classes is highly beneficial for our task. In this way, we can reduce tracker inaccuracies and prevent drifting, thus increasing the tracker’s stability.
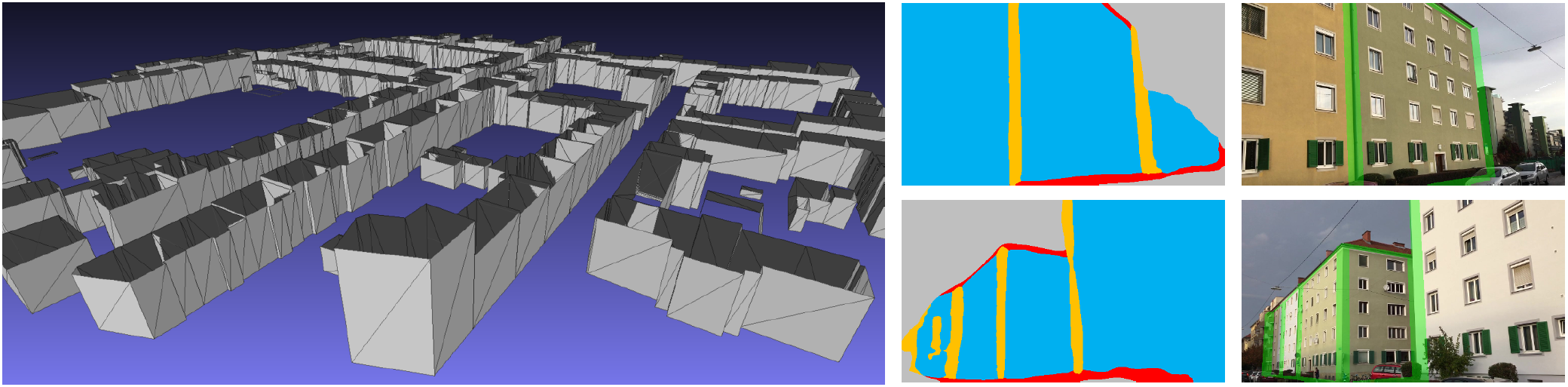
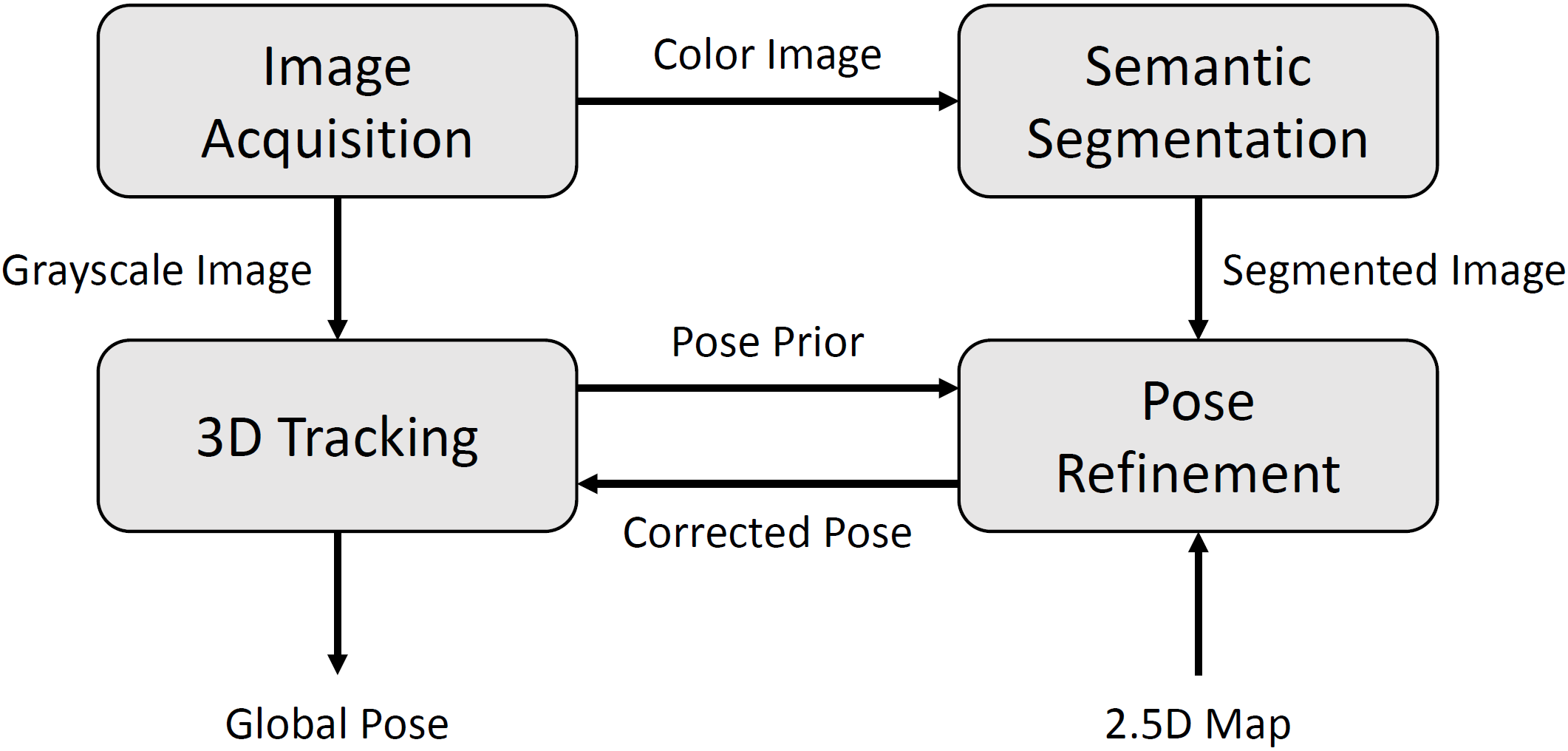
In particular, the input frame is first forwarded to a 3D tracker and to a CNN-based segmentation stage, giving us a rough estimate of the camera pose and a semantic segmentation of the image. This information is then used in the pose refinement stage, where we first sample pose hypotheses around the estimated pose prior and then compute a 3D rendering of the city model for each hypothesis. The core idea now is to find the pose hypothesis that optimally aligns the rendering with the segmentation, finally yielding a more accurate estimate of the camera pose than the prior provided by the tracker.
Results
We evaluate our approach for two different challenging scenarios, also showing that it is generally applicable in different application domains and that we are not limited to a specific tracking method. First, we demonstrate our method on several challenging sequences from a handheld camera using SLAM. In the following figures, the semantic segmentation of the input frame is shown in the top row, the registration with a SLAM-based tracker overlaid over the input frame in the middle row, and the registration with our method overlaid over the input frame in the bottom row.

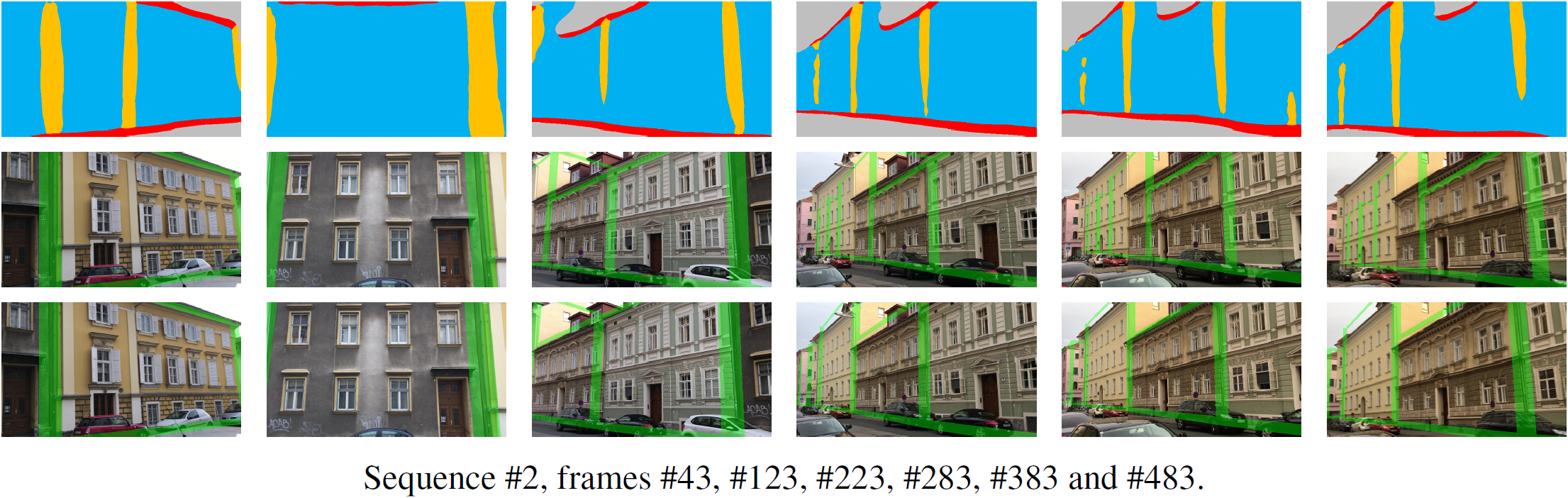
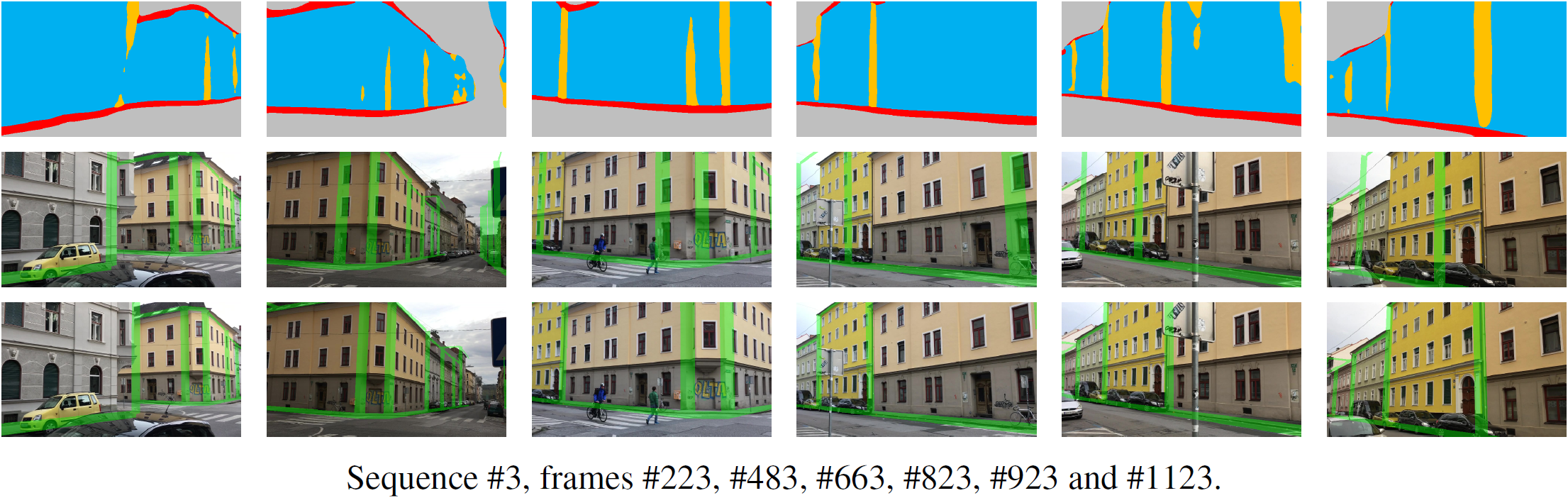



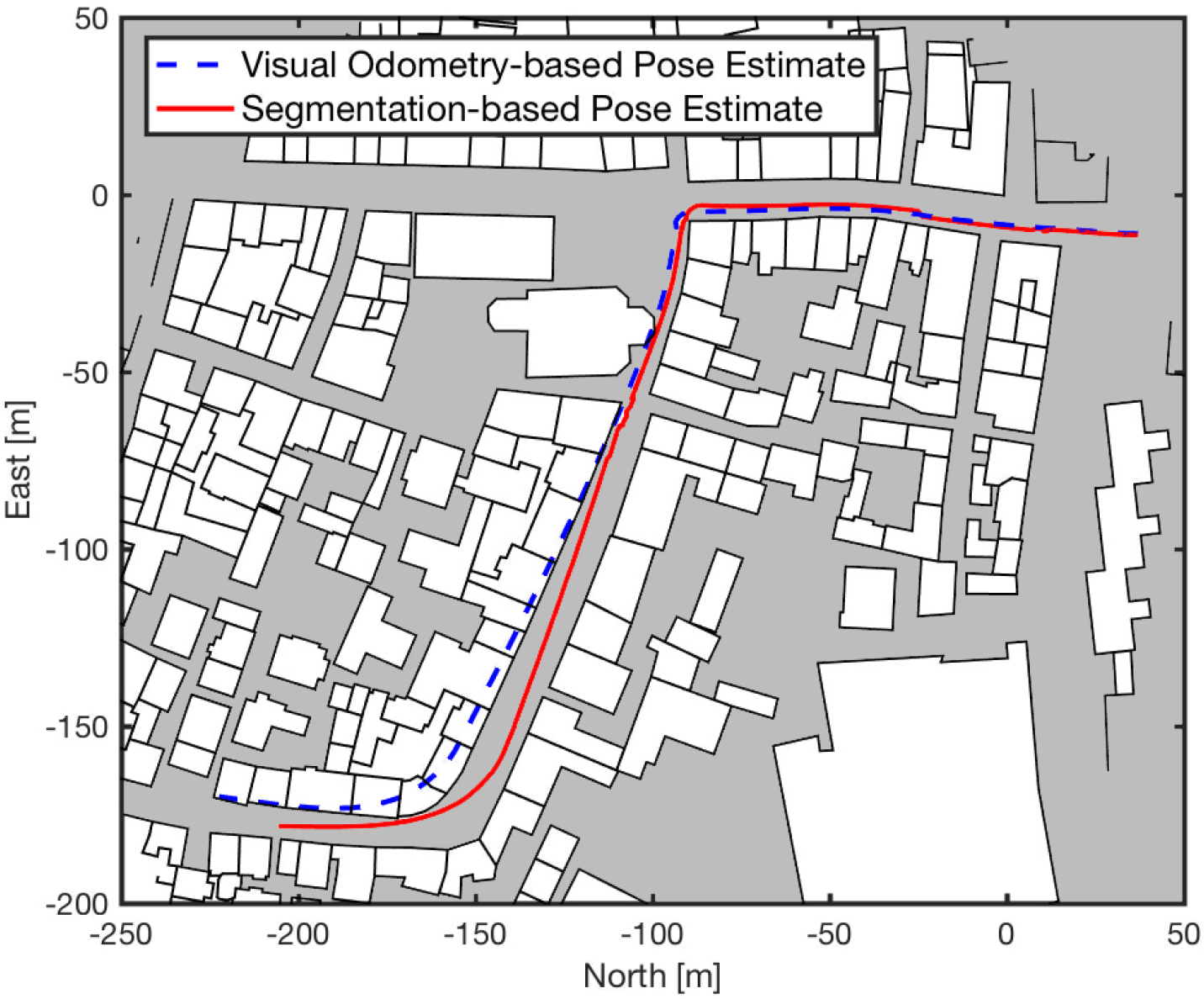
In a second experiment, we combine our pose estimation method with a visual odometry tracker and demonstrate its capability to correct drift on Sequence #18 from the KITTI benchmark. The following figure shows the trajectory estimated by the visual odometry tracker (dotted blue line) and the corrected trajectory using our segmentation-based pose estimation (solid red line).
This work was supported by the Christian Doppler Laboratory for Semantic 3D Computer Vision, funded in part by Qualcomm Inc.

We also thank NVIDIA for the donation of a Titan Xp GPU to support our research.
Corresponding Publication(s):
Efficient 3D Tracking in Urban Environments with Semantic Segmentation
Martin Hirzer, Clemens Arth, Peter M. Roth, and Vincent Lepetit
In Proc. British Machine Vision Conf. (BMVC), 2017