
Generalized Feedback Loop for Joint Hand-Object Pose Estimation
We propose an approach to estimating the 3D pose of a hand, possibly handling an object, given a depth image. We show that we can correct the mistakes made by a Convolutional Neural Network trained to predict an estimate of the 3D pose by using a feedback loop. The components of this feedback loop are also Deep Networks, optimized using training data. This approach can be generalized to a hand interacting with an object. Therefore, we jointly estimate the 3D pose of the hand and the 3D pose of the object. Our approach performs en-par with state-of-the-art methods for 3D hand pose estimation, and outperforms state-of-the-art methods for joint hand-object pose estimation when using depth images only. Also, our approach is efficient as our implementation runs in real-time on a single GPU.
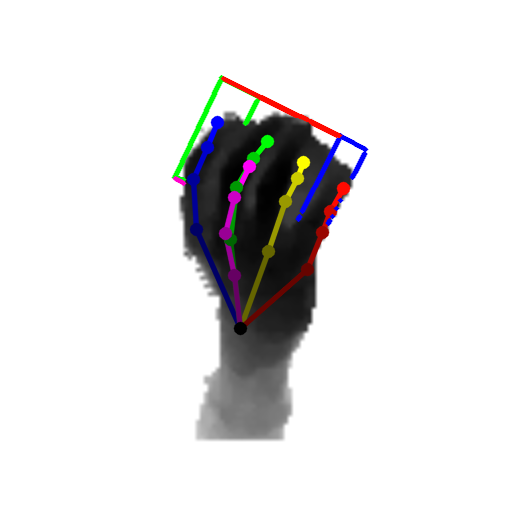
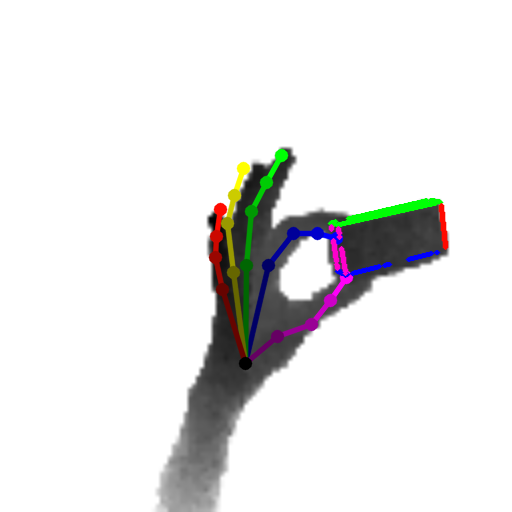
Our method can predict the 3D pose of the hand and the object jointly from single depth images. Samples are objects from the DexterHO dataset (cubes) and our own sequences (rubber duck). The images show the estimated 3D hand skeleton and 3D bounding box of the object projected to the image.
 | 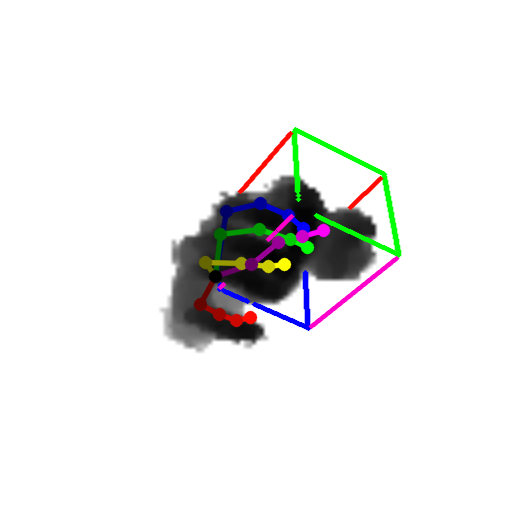 |  |
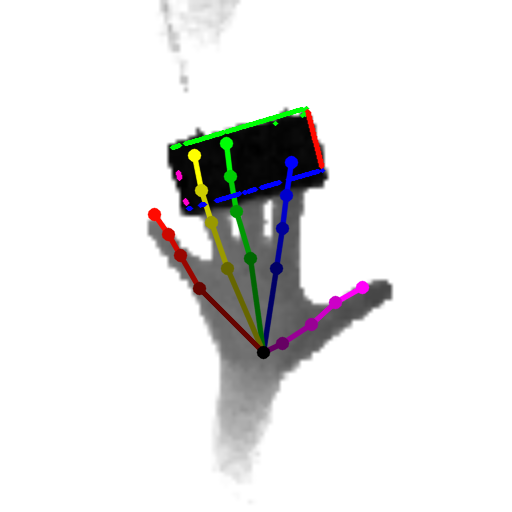 |  | 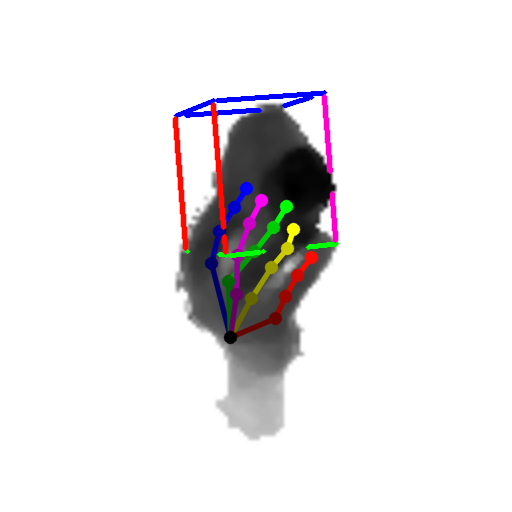 |
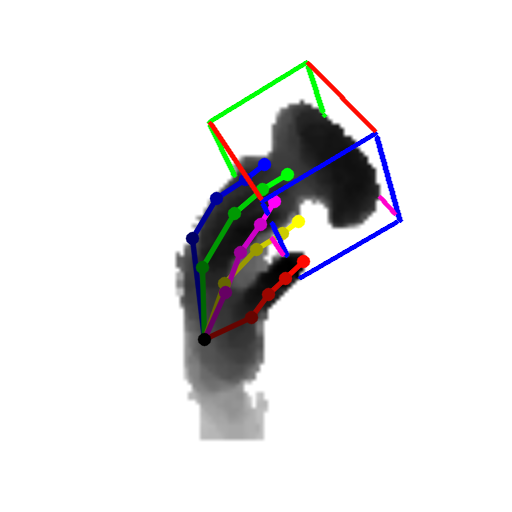 |  |  |
Material
Our results: Each line is the estimated pose of a frame. The pose is parametrized by the locations of the joints in (u, v, d) coordinates, ie image coordinates and depth. The coordinates of each joint are stored in sequential order.
- NYU dataset of J. Tompson: Generalized Feedback
- DexterHO dataset of S. Sridhar: Revised annotations, Generalized Feedback predictions with 21 hand joints (tips are index 4, 8, 12, 16, 20) and 3 object corners