
IDE@S Anwendungsbeispiele eines organisationsübergreifenden Datenaustausch
Anwendungsbeispiel µCT
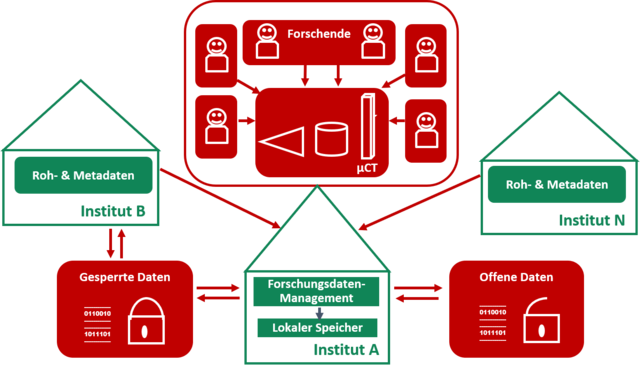
Ein Konsortium von 13 Instituten aus drei Universitäten organisiert die gemeinsame Nutzung eines Röntgen-Micro-Computertomographen (µCT). Dieses Gerät wird vor allem der Grundlagenforschung dienen und insbesondere wird die Dynamic Computed Tomography (DCT) verwendet. Es werden Daten zu verschiedensten Bereichen erhoben, unter anderem für die Erforschung von Nierensteinen, die Untersuchung des Fibrillenwinkels von Papierfasern in Papierproben, die Erforschung von polymorphen Strukturen in Tabletten und die Untersuchung der Texturentwicklung in Metallen. Des Weiteren wird unter Einbindung einer in situ Einheit für kontrollierte Umweltbedingungen der Einfluss der Luftfeuchtigkeit auf die Porenstruktur von Papier, den Gefrierprozess von Wasser in Beton, oder die Korrosion von Schweißnähten untersucht. In der interdisziplinären Zusammenarbeit wird auch die Erforschung der Auswertungsmethoden der µCT Daten durch regelmäßige User Meetings ein wichtiges Ziel der Forschung sein. Die Art der Segmentierung ist stark materialabhängig, wodurch verschiedene Gruppen Know-how in verschiedenen Segmentierungsmethoden haben. Aus der Verbindung dieser Erfahrungswelten werden neue Einsichten im Bereich der Segmentierung und der dazu gehörigen Bildbearbeitung erwartet. Als Basis für die unterschiedlichen Forschungsfelder soll eine Datenmanagementplattform mit Weboberfläche für die Verwaltung und den Austausch von Rohdaten sowie zugehörigen Metainformationen dienen, welche Arbeitsabläufe und Datenarchivierung erleichtern sollen. Die Open-Source Softwarelösung für das Datenmanagement beinhaltet regelmäßige Updates und langfristigen Support von den Entwicklerteams. Unterstützt werden diverse Authentifizierungsprotokolle, Austausch auf Basis von Zugriffsanfragen, strukturierte Ablage von digitalen Objekten durch die Oxford Common File Layout Spezifikation, unterschiedliche Exportformate und Aktualisierungsautomation. Zugehörige Sicherheitsstrategien und Leitlinien sind in Bearbeitung. Die Hauptspeicherinfrastruktur wird von einem der kollaborierenden Institute gestellt und die Installation der Datenmanagementsoftware zur Anbindung weiterer Systeme erlaubt.
Anwendungsbeispiel Smart Energy Systems

Eine Datenplattform verknüpft mit einer Infrastruktur für Internet-of-Things am Campus der TU Graz wurde durch das Institut für Softwaretechnologie entwickelt und wird unter anderem für verschiedene Energiedienstleistungen genutzt, beispielsweise von TU Gebäude und Technik oder EAM Systems. Ein federführendes Projekt hat die Bereitschaft, zugehörige Daten bereitzustellen, untersucht, und verweist auf essentielle Kommunikationsaspekte für eine aktive Einbindung von Nutzer*innen zukünftiger Energiesysteme. Eines der laufenden verknüpften Projekte zielt darauf ab, Energiesysteme mit stark fluktuierender Nutzung und großen Anteilen volatiler Energiequellen zielgerichteter betreiben und planen zu können. Ein weiteres Projekt soll das Konzept eines smarten nachhaltigen Campus ausbauen, basierend auf Überwachungsalgorithmen unter Einbindung von Daten einer Echtzeitkommunikation der IoT Lösung. Im Laufe eines wesentlichen Projekts sollen unterschiedliche Aspekte wie Datenzugriff, transparente Kontrolle und Datenschutzkonzepte für sensible Informationen der Nutzer*innen erarbeitet werden.
Anwendungsbeispiel CyVerse
Aus dem Bereich der Life Sciences ist eine kollaborative Umgebung für Datenmanagement und Datenanalytik von großen Datenmengen universitätsübergreifend hervorgegangen um die Wissenschaft durch Daten-getriebene Entdeckungen zu stärken. Die verteilte rechengestützte Architektur zur Datenorganisation und web-basierter Datenanalyse soll Forschende aus verschiedensten Disziplinen zusammenbringen und in ihren Tätigkeiten unterstützen. Die hiesige Cyverse Variante läuft über mehrere Universitäten unter der Organisation des BioTechMed Graz Konsortiums und soll österreichweit durch ein aktuell laufendes Projekt ausgeweitet werden. Die amerikanische Variante der Cyberinfrastruktur hat eine vergleichsweise längere Historie und bietet bereits viele Services inklusive abgesicherter Datenspeicherung, bioinformatischer und interaktiver web-basierter Analyseprogramme, Visualisierung, Cloudanbindung an Rechen- und Speicherserver, und Schnittstellen zur Implementierung eigener Prozesse. Die amerikanische Variante wird von der University of Arizona zusammen mit dem Texas Advanced Computing Center sowie Cold Spring Harbor Labor organisiert. Als ein Nutzungsbeispiel werden definierte Arbeitsabläufe zur Klärung von biomedizinischen Fragenstellungen automatisiert über die Plattform abgearbeitet und reproduzierbar für die gesamte Anwendergemeinschaft über Containersysteme bereitgestellt. Die Basis des eingebauten Datenmanagements betrachtet bereits etablierte Standards und Metadatenabfragen aus dem Life Science Bereich. Eine Grundidee der Umgebung ist Daten, Softwarelösungen und andere Ressourcen im Sinne der „FAIR Data“ Prinzipien frei verfügbar zu machen. Die Sicherheitsstrategie basiert vorweg auf den Richtlinien der ersten Instanz einer Kerninstallation unter Datenschutzgrundverordnung bzw. GDPR Einhaltung und baut dann weitere Richtlinien und Standards der Partnerorganisationen mit ein, wobei bei Überschneidungen im Zweifelsfall die strikteren Regelungen bevorzugt werden.
Anwendungsbeispiel Datenkreise Health
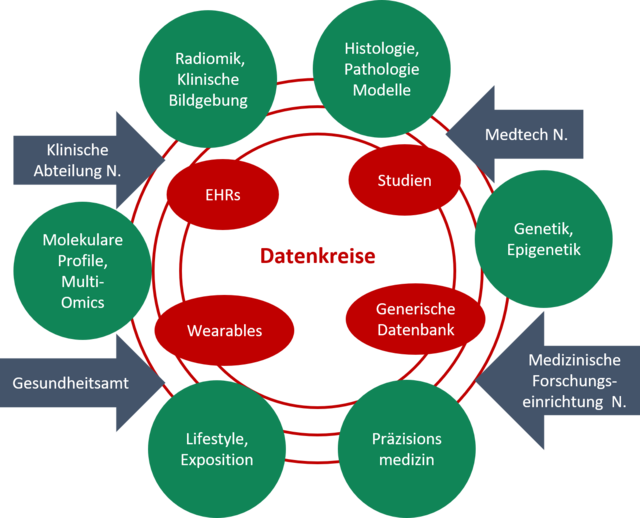
Ein Projektkonsortium von Forschungseinrichtungen und Entwicklungsunternehmen will die Nutzung von medizinischen Trainingsdaten für Künstliche Intelligenzmodelle aus fragmentierten Datensilos ermöglichen. Datensilos sind isolierte Datenspeicher unter der Kontrolle einer Organisation oder Instanz. Diese sollen für die Modellentwicklung verfügbar gemacht werden. Die Idee der Datenkreise soll Datenanbietende und Datennutzende zusammenbringen und darüber hinaus neue Anwendungsszenarien liefern. Eine Grundlage soll Datenschutz, Datenqualität und Privatsphäre spielen, um primäre Hürden und Bedenken wie mangelndes Vertrauen gegenüber einen Datenmarktplatz abzufangen.
Im Zuge des Projekts sollen für den Aufbau zukünftiger Datenkreise relevante Stakeholder zusammengeführt und auf deren individuelle Bedürfnisse eingegangen werden. Weiters sollen ethische Aspekte sowie berufspolitische Barrieren behandelt werden. Diese Punkte dienen als Anforderungen an den Datenkreis um einen Mehrwert des Datenaustausches zu bewirken. Darauf aufbauend werden Schnittstellen und technische Lösungen für Datenprozessierung und Qualitätssicherung entwickelt sowie ein rechtlicher Rahmen definiert. Eine Bemessung des Datenwerts soll entwickelt werden und als Mehrwert für beteiligte Stakeholder fungieren.
Bestehende Lösungsansätze für Datensicherheit und Datenautonomie für eine dezentrale Datenerhebung wird um die Nutzbarkeit von Trainingsdaten für Künstliche Intelligenzmodelle erweitert. Hier werden Qualitätsstandards auf Metaebene integriert und auf Leitfäden um Best Practices gesetzt. Datenschutz soll über Stakeholder kontrolliert werden, die den Zugang zu ihren Daten je nach Verwendung selbst setzen. Dies soll auch den Datenfluss nachvollziehbar machen, während Konformität mit nationalen und internationalen Regulierungen gestärkt wird. Die rechtliche Expertise fließt neben Datenqualität, Kryptographie sowie erklärbarer künstlicher Intelligenz durch Projektpartner ein.
Bei der Nutzung von Gesundheitsdaten sollen Diversitätsaspekte berücksichtigt werden um Diskriminierung durch Künstliche Intelligenz zu vermeiden. Zusammengeführte Projektergebnisse sollen der Allgemeinheit zugänglich und verfügbar gemacht werden
Dr Miguel Rey Mazón (m.reymazon@tugraz.at) Projektmanager
Institute for Interactive Systems and Data Science (ISDS)
Haus der Digitalisierung, Brockmanngasse 84, 8010 Graz
Technische Universität Graz