
Showcase Projects:
Generating Synthetic Data:
To use ML technology for geotechnical applications, at first it is necessary to provide ML with a learning dataset, ideally based on real-world data. However, real-world datasets have many drawbacks, such as the need to record, acquire, and organize them. Additionally, geotechnical datasets are often limited in quantity, exhibit skewed distributions, and hence might only fulfill some requirements for certain geotechnical tasks. In addition, confidentiality issues constrain possibilities for the publication of available geotechnical datasets. All these factors significantly limit the development and use of tailored ML algorithms.
Synthetically generated datasets can provide relief in many of the situations restricting the use of real data. Data synthesis is primarily about generating new, unprecedented data to be used for ML model evaluation and training.
To bypass the problems arising from using real data, we explore the possibility of employing a generative adversarial network (GAN) based approach to generating synthetic geotechnical data. The demands we put on the synthetic data are of a dualistic nature. On the one hand, the data has to be sufficiently dissimilar to the original data so that it does not create confidentiality issues (demand for originality). On the other hand, it has to show the same patterns and follow the same rules as the original data so that it can be used as if it were real data (demand for conformity).
Our experiments in applying a tailored WGAN trained on real observations show that it is possible to generate new, synthetic, and realistic tunnel boring machine (TBM) operational data. After evaluating the synthetic data, we confirm that both imposed demands are fulfilled.
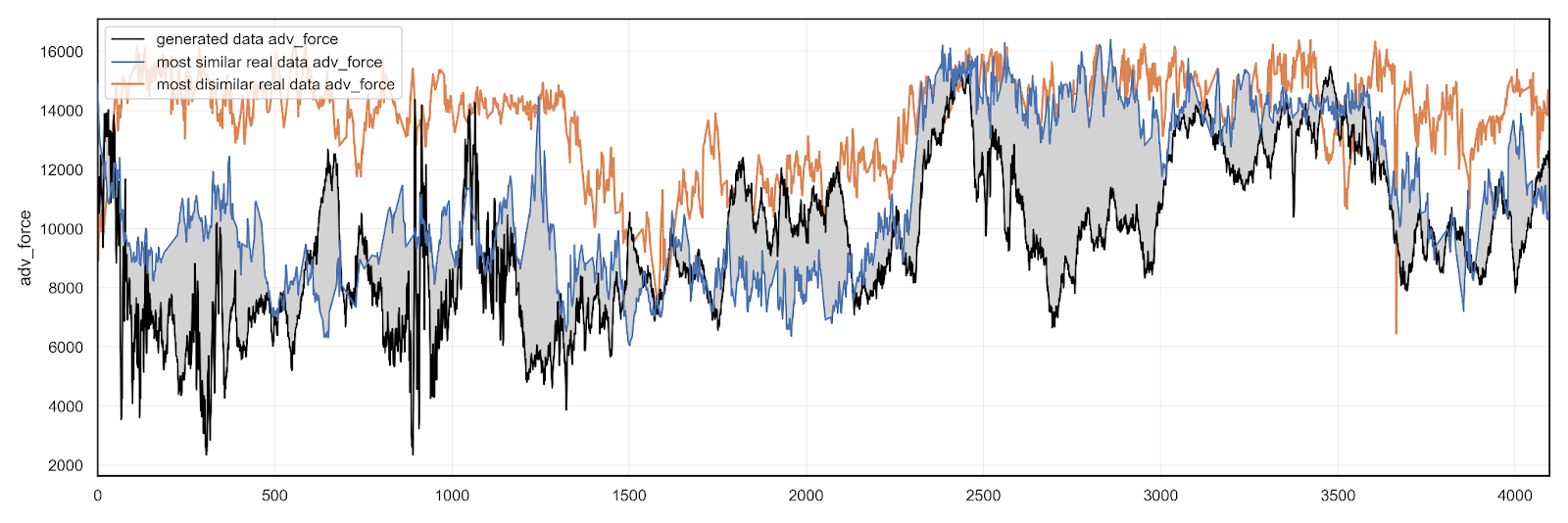
Synthetic data here compared to the most similar and most dissimilar real TBM data, where the Euclidean distance between every set of synthetic and real data determined the similarity.
[ GENERATING SYNTHETIC TBM OPERATIONAL DATA USING GENERATIVE ADVERSARIAL NETWORKS (GANs)
by Paul J. Unterlass, Georg H. Erharter, Alla Sapronova, and Thomas Marcher]
Tunnel Advance Decision Assistance (TADA):
Decisions made during tunnel construction are based on the experts’ opinions on site. Because every tunnel is unique only to some extent, it can be assumed that decisions are often "reinvented". Given the number of completed, ongoing, and planned tunnel projects in Europe and worldwide, it is possible to identify projects that could be used as an extra reference to assist the decision-making processes for new constructions. For that, one needs to obtain data from past projects, identify " similar " projects to the project of interest, and use data from these past similar projects to train predictive models.
The main issue for obtaining data from past projects is that most documents in civil engineering, especially those created in the early- to mid-digitalization era, are stored as papers or files containing unstructured information (e.g., scanned documents). Such documents may include, e.g., handwritten notes, engineering sketches, printed plots, and photos. Meanwhile, the form and completeness of the documents vary from one project to another. To utilize the available information, there is a need to extract structural data from archived geotechnical documentation.
The TADA project seeks to optimize safety, time, and cost in construction processes by preserving valuable knowledge from previous excavations. To do that systematically, TADA aims to deliver a framework that can automatically extract information from (historical) engineering documentation, harmonize and store the extracted information in a structured format, and use the data science and AI/ML techniques to develop predictive models for near real-time decision support in tunneling.
|
|
||||||||||||||||||||||||
|
|

Tunneling Process Optimization and Risk Assessment and Management:

Integration of smart techniques for tunnel seismic applications
Applications of seismic measurements for predicting hazard zones are practiced in many tunnel drives in rock mass today. Next to a large exploration range and accurate localization of discontinuities, seismic data provide attributes for a better characterization of the ground conditions. A good synchronization of all technical components is required to obtain optimum data quality and quantity while the tunnel excavation is not obstructed. Firstly, the signal source must feed as much energy as possible into the rock in a very short time. Secondly, the continuity of the signal generation with constant quality and its precise timing by means of wireless data transmission also ensures a reliable measurement process.
Artificial intelligence is used to determine the quality of the recorded data already in the tunnel, and feedback is given to the user keeping the data quality high. From the tunnel site, the recorded raw data can be transferred to a cloud, from where an authorized processor collects them wherever in the world. An immediately started data processing produces a result within an hour that includes a geological forecast for the next 150 meters of tunnel advance.
In addition to data quality, the quality of the results is crucial. Therefore, techniques are currently under development using ML to correlate and analyze seismic attributes with geological properties.
In the joint work with AMBERG TECHNOLOGY, we are exploring an intelligent path for reducing labeling subjectivity and improving the quality of prediction for the geological information ahead of the tunnel face. Implementation of unsupervised classification algorithms into the workflow has been proven to eliminate subjective perceptions of engineers and improve the reproducibility of evaluation results. This, in turn, enhances the applicability of results to be used for "feeding" into consequent prediction systems.
[Eliminating Subjective Labelling for Improved Accuracy in Geological Predictions,
by Paul Johannes Unterlas, Alla Sapronova, Thomas Dickmann, Jozsef Hecht-Méndez, and Thomas Marcher]
Utilizing MWD from drilling and blasting, we assess data from past projects to identify risks and develop effective strategies to mitigate them.
The primary objective of the project is to estimate over-excavation volumes by finding the correlations between over-excavation 1D, 2D, or 3D metrics and a combination of MWD data and supplementary technical information (e.g., drilling geometry, the volume of explosives used).
The research questions guiding this study are:
- What patterns and relationships exist within the collected data that can help predict over-excavation?
- How accurately can ML models estimate over-excavation in tunnel construction?
The project aims to advance predictive analytics for tunneling operations using ML techniques by answering these questions.
To achieve the project's primary objective, the following steps are undertaken:
- Data Inspection and Preprocessing: This step includes initial data cleaning, parsing, and organization of the collected data to prepare it for analysis.
- Data Analysis: Includes utilization of intelligent analytics techniques to examine the MWD data, identifying relevant patterns and correlations.
- ML Model Training and Assessment: This step focuses on the implementation and evaluation of ML models to assess their accuracy in estimating over-excavation.
The model's performance is different in predicting over- and under-excavation, which can be traced back to the imbalance in the training data. Specifically, the dataset contains more recorded events of over-excavation compared to under-excavation. This skewness leads the model to be more proficient at predicting over-represented scenarios in the training set.
In this study, we explored various factors influencing the performance of ML models. One clear observation was the impact of feature selection on the model’s accuracy. While using all available features often resulted in increased training accuracy, it didn't necessarily improve the model's performance on the test set. On the contrary, when we used only important features as inputs for training, a significant improvement in test accuracy was observed. This was particularly true for shallow regression models, suggesting that a more focused set of features contributes to better model generalization.
Assistant Prof. Alla Sapronova
Email: alla.sapronova@tugraz.at
Office hours:
Tuesday to Thursday from 12 to 2 p.m.
BSc MSc Paul Johannes Unterlaß
Tel. +43 316 873 - 4227
Email: unterlass@tugraz.at